
프롤로그
aws 우분투 서버 하나 파서 연습
C언어의 상수, 변수, 자료형, 오버플로우와 언더플로우, 변수 선언 방법/규칙, 주석처리
상수와 변수
수학적인 개념으로 상수와 변수를 알아보자.
4x-3 = 1이렇게 있을 때, -3은 변하지 않는 값, x는 변하는 값이다.
x의 값은 1, 2, 3, 4, 5, ....1.1, 1.2,....pi...등 여러 개의 값들이 올 수 있고, x에 값에 따라서 해당 식이 참이 될 수도, 거짓이 될 수도 있다.
이렇기에 x는 변하는 수, 즉 변수라고 한다.
반면에 -3 같은 경우에, 해당 식에서 절대로 변하지 않는다. 1도 마찬가지다. 이를 상수라고 한다.
그렇다면 x 앞의 4는? 저건 계수라고 하는데, 일단 상수와 변수의 값만 볼 것이니까...
이게 C언어 뿐만 아니라 다른 프로그램 언어에서도 똑같이 적용된다.
상수를 지정해놓으면, 해당 프로그램이 끝나거나 해당 코드가 바뀔 때까지 절대 바뀌지 않게 되는 수를 상수라고 한다. C언어 같은 경우
#define PI 3.141592
const int a = 3;이런식으로, const를 붙여서 저 a라는 값은 3에서 절대로 바뀌지 않는 다는 것을 명시한다.
또는 #define로 상수를 미리 지정하는 방법도 있다.
반면에 변수는 변할 수 있는 값이다.
int b = 3;일단은 저렇게 b라는 값에 3을 집어넣었지만, 후반에 b=5로도 변경될 수도 있고, b=7로도 변경될 수도 있고 계속하여 계산하다가 바뀔 수 있다.
그럼 상수와 변수는 왜 필요한가?
상수의 경우에는 변하지 않는 값을 명확히 나타내기 위해 사용된다. 예를 들어, 수학에서 파이(π)의 값이나 변하지 않는 설정 값을 저장할 때 유용하다. 코드가 돌아가면서 값이 바뀔 때 큰 타격이 발생할 경우가 있을 수 있는데, 그것을 방지하기 위해서 쓰인다.
변수의 경우에는 프로그램의 상태를 저장하고 변경해야 할 때 사용된다.. 예를 들어, 사용자 입력을 받아 처리하거나, 계산 결과를 저장할 때 사용된다. 그래서 어지간한 케이스 아니고서는 보통 변수로 정의하고 사용한다.
const의 유무에 따라서 변수가 되기도 하고, 상수가 될 수 있다는 것을 알았다. 그럼 중간에 놓인 저 int라는 것은 무엇인가?
밑에 자료형에서 알아보자.
자료형
부호가 있는 정수형
| short (short int) | 2byte (16bit) | -32,768 ~ 32,767 |
| int | 4byte (32bit) | -2,147,483,648 ~ 2,147,483,647 |
| long (long int) | 운영체제 마다 다름. 리눅스에서는 8 | 운영체제마다 다름. 리눅스에서는 8 |
| long long (long long int) | 8byte (64bit) | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 |
short, int, long, long long 이있는데, 뒤에 int를 붙여도 되고, 안 붙여도 된다.
범위같은 경우는 int 의 경우 4바이트, 즉 32비트를 사용하니가 -2^31 ~ 2^31 -1 인 범위이기에 저렇게 표시가 된다.
실제로 저것의 크기가 맞는지 확인해볼까?
nano a.c로 아래글을 작성한다.
#include <stdio.h>
int main() {
int a = 0;
short b = 0;
long c = 0;
long long d = 0;
short int e = 0;
long int f = 0;
long long int g = 0;
printf("%zu, %zu, %zu, %zu, %zu, %zu, %zu\n", sizeof(a), sizeof(b), sizeof(c), sizeof(d), sizeof(e), sizeof(f), sizeof(g));
return 0;
}코드 디테일은 나중에 히해하고, 일단은 각 자료형별로 몇 바이트를 차지하는지에 대한 코드이다.
gcc -o a a.c
./a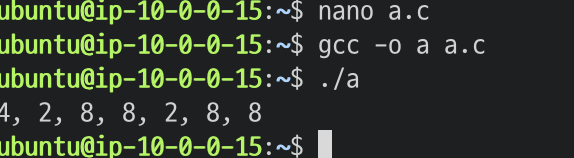
하면, int =4, short = 2, long = 8, long long = 8인 것을 확인할 수 있다.
long이나 short 뒤에 int를 붙인 것도 마찬가지.
이 Long이라는 게 원래 4바이트로 알고있었는데 운영체제마다 다르다고 한다. 우리가 쓰고 있는 우분투 리눅스에서는 long을 8바이트로 인식한다. 옆 친구 윈도우로 저 코드 돌려봤을 떄는 Long이 또 4바이트로 나온다. 우리는 리눅스에서 할 거니까..8로 알아두자.
부호가 없는 정수형
| unsigned short | 2byte (16bit) | 0 ~ 65,535 |
| unsigned int | 4byte (32bit) | 0 ~ 4,294,967,295 |
| unsigned long | 운영체제 마다 다름. 리눅스에서는 8 | 운영체제마다 다름. 리눅스에서는 8 |
| unsigned long long | 8byte (64bit) | 0 ~18,446,744,073,709,551,615 |
아까랑 똑같다. 다만 , unsigned가 붙어서 부호가 없기에, 0부터 시작한다.
short와 unsigned short를 한 번 비교해보자.
#include <stdio.h>
int main(){
short a = 65500;
unsigned short b =65500;
printf("%d, %d", a, b);
return 0;
}short 자료형인 a와, unsigned short인 b가 있고 전부 65500을 집어넣어줬다.
short의 경우32767까지밖에 저장이 안 되는데...65500을 넣어준거다.
unsighed short는 65535까지 저장되니까 저렇게 냅두자.
그래서 위대로 출력을 해보면

a가 -36, b는 65500이 나왔다. 이상하다, a가 -36이 나온다. 65500을 넣었는데. 왜냐면 자료형에 저장할 수 있는 값을 초과했기 때문이다. 왜인가? 이는 아래에 오버플로우 언더플로우 부분에서 설명하겠다. 다른 자료형들 부터 알아보고, 밑에 오버플로우 부분에서 확인해보자.
문자형
char가 있다. 얘도 똑같이 unsigned char이 있다.
| char | 1바이트(8비트) | -128~127 |
| unsign char | 1바이트(8비트) | 0~255 |
문자 한 글자를 저장한다. 그러니까 이제 저장이 되면 아스키코드값으로 저장되기에, 아스키코드가 또 7비트짜리이지 않는가...
그게 저장이 되는 것이다. 즉 A라고 하면 아스키코드값 65이기에 해당값이 저장이 되는 거고, 여기에 +1연산을 하면 B가 저장이 되는 방식이다. 이부분은 차차히 알아가보도록 하고, 아무튼 똑같이 실습을 통해서 확인해보면
#include <stdio.h>
int main(){
char a = 'A';
char b = 'B';
printf("value of A : %d, %c\n", a, a);
printf("value of B : %d, %c\n", b, b);
a = a+1;
printf("value of a : %d, %c\n", a, a);
return 0;
}이걸 실행시켜보면

아스키코드값 65인 A가 저장이 되는 것이다. 그래서 1비트가 필요한 거다. 그리고 65에서 +1을 한 66은 아스키코드값 B이기에, A에서 +1을 해준거는 B가 되는 것이다.
이때 주의해야할 점은 파이썬은 ""든 ''든 상관없었는데, 한 글자 저장할 거면 ''로 해줘야한다.
실수형
얘도 부호 없는 unsigned 있는데 생략하겠다.
| float | 4바이트 (32비트) | 소수점 이하 6~7자리 |
| double | 8바이트 (64비트) | 소수점 이하 15~16자리 |
| long double | 컴파일러마다 다름 우분투는 16 | 소수점 이하 약 18~21 또는 그 이상 |
또 long이 문제다.
#include <stdio.h>
int main(){
float a = 3.141592f; //소수뒤에 f를 붙여줘야 float형이라는 것을 명시
double b = 3.141592; //소수 뒤에 아무것도 안 붙이면 기본 double형
long double c = 3.141592L; //소수뒤에 f를 붙여줘야 long double형이라는 것을 명시
printf("a : %f, size : %zu\n", a, sizeof(a) ); //float와 더블 모두 f
printf("b : %f, size : %zu\n", b, sizeof(b) );
printf("c : %Lf, size : %zu\n", c, sizeof(c) );
return 0;
}로 크기 확인해보면

4, 8, 16 이렇게 나온다. 아! long double 은 16이구나!
중간에 보면 실수 뒤에 f, L등이 있는데, 저것들을 붙이지 않으면 double로 인식한다. float같은 경우에는 형변환으로 인하여 크게 상관은 없지만,... long double에 double들어가면 뒷부분 표시 못한다.
a값에다가 조금 변경을 줘보자.
#include <stdio.h>
int main(){
float a = 3.14159212345f; //소수뒤에 f를 붙여줘야 float형이라는 것을 명시
printf("a : %.15f, size : %zu\n", a, sizeof(a) ); //15자리까지 표시
return 0;
}3.14159212345로, 소수점 아래 6~7까지 표현한다는 float에다가 소수점을 더 주고, 소수점 밑 15자리까지 출력시켜보았다.

딱 3.141592까지만 일치하고 그 뒷부분은 일치하지 않는다. 왜냐? 나머지 뒤의값은 저장하지 못해서 쓰레기값으로 존재하는 거기 때문.
이 소수점 원리를 이해하기 위해선 부동소수점이라는 개념을 알고 있어야한다.
부동소수점
소수점을 저장하기 위해서는 특별한 방식(?)을 이용한다.
float를 예시를 들자면, 4바이트 총 32비트이지 않는가?
첫 1비트는 소수부, 그다음 11비트는 지수부, 나머지 23비트는 가수부로 표현한다.
| 부호(1비트) | 지수(8비트) | 가수(23비트) |부호는 대충 +- 표현하는 거니까 넘어가겠고,
10진수로 예시를 들자면
1023을 표현한다면 1.023 * 10^3으로 표시할 수 있다. 지수부에는 10^3에서 3이 들어가는 거고, 가수부는 1023이 들어가는 느낌이라고 보면 된다. 근데 컴퓨터는 이진수잖아요? 그래서 이 방법이 이진수에도 똑같이 적용이 되고, 이진수가 적용된 게 부동소수점인것이다.
즉 1.0101 * 2^4 이러면 4는 100이니까 지수부에는 00000100이 들어가는 거고, 가수부에는 10101이 들어가는 것이다. 그리고 양수니까 첫비트는 0 이런식으로 소수점은 표시한다.
double이라면?
| 부호(1비트) | 지수(11비트) | 가수(52비트) |요렇게 표시!
오버플로우와 언더플로우
아까 위에서, short 에다가 65500값 넣었을 때 이상한 값 나왔던 것을 기억하는가? 오버플로우 때문이라고 한다.
오버플로우(Overflow)와 언더플로우(Underflow)는 컴퓨터에서 수의 범위를 벗어나는 상황에서 발생하는 현상이다. 아까 변수를 선언하고, 해당 변수는 int형을 담는 자료형이야! 라고 선언을 했는데 int형의 범위를 벗어났을 때 발생한다고 보면된다. OverFlow뜻은? 넘쳐흐른다, 즉 값이 허용범위의 최대값을 초과했다, short가 약 -25000~25000까지인데, 25000을 벗어났을 경우에 오버플로우인 거고, 반대로 -26000이렇게 허용범위의 최솟값보다 작아진경우 이때는 언더플로우라고 한다.
오버플로우(OverFlow)
오버플로우는 프로그램에서 사용되는 수가 자료형이 표현할 수 있는 최대값을 초과할 때 발생한다고 했다. 밑에 예시를 보자.
#include <stdio.h>
int main() {
int maxInt = 2147483647; // int의 최대값
int result = maxInt + 1; // 오버플로우 발생
printf("결과: %d\n", result); // 비정상적인 음수 출력
return 0;
}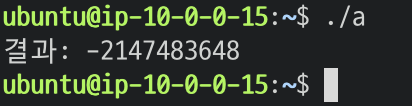
이야 2147483647 에서 +1을 했을 뿐인데 완전히 최소범위로 내려갔다. 원리까지 설명을 한다면...
int형이 32비트인 4바이트인데, 2147483647 이라면 2진수 비트값으로 표현하면
0111111......111 //총 32자리, 0이 1개, 1이 31개이렇게 표현이 될 것이다. 여기서 +1을 해준다면?
10000000....000 #맨앞자리 1, 나머지 31자리는 0맨 앞은 양수 음수를 표현하는 부호값이다. 즉 부호값이 1로 바뀌고 나머지값은 0으로 바뀌었는데, 2의 보수 체제로 인하여 해당값은 -2147483648이 된다. 이게 오버플로우 부호 부분에 변경이 발생했다.
실수형도 오버플로우가 발생할 수 있는데, 실수형에서는 오버플로우 발생시 무한대로 값이 간다.
언더플로우(UnderFlow)
오버플로우는 최대값을 넘어섰기에 발생했다면 언더플로우는 반대로 최소값을 넘어서서 발생한다.
정수형 부터 볼까?
#include <stdio.h>
int main() {
int minInt = -2147483648; // int의 최소값 (32비트)
int result = minInt - 1; // 언더플로우 발생
printf("결과: %d\n", result); // 최대값으로 순환되어 출력됨
return 0;
}
아까랑 같은 원리다.
100000000....0 에서 -1을 빼면 011111....11111이 되는데 부호가 바껴버리면서 최대값이 되었다.
실수형에서 언더플로우는 값이 0으로 수렴하거나 너무 작은 값이 손실된다.
그래서 조심해야한다
변수 명명 방법과 규칙
위에서 계속 코드는 보였을 텐데
자료형 변수명;
자료형 변수명 = 초기값;이런식으로 사용을 한다.
변수는 변하는 수라고 했는데, 그것을 x로 저장하고 싶다. 근데 그 그릇의 종류는 int형으로 하고 싶다?
int a;이렇게 넣어버리면 되는 거고, 근데 아예 초기값도 넣어버리고 싶다?
int a = 3;이렇게 하는 것이다.
변수를 저장하는 , 즉 변수의 값을 저장하는 변수의 이름을 선언하는 데에도 규칙이 있다.
- (1) 첫글자는 반드시 영문자 또는 _만 가능 (숫자 ㄴㄴㄴ)
- int myVar; // 올바름 int _count; // 올바름 int 2number; // 잘못된 선언 (숫자로 시작)
- (2) 대소문자는 구분한다
- int count; int Count; // 별개의 변수
- (3) 예약어는 사용불가능하다.
- int for; // 잘못된 선언 (예약어 사용)
변수 이름 근데 좀 많이 쓰다보면 단어가 길어지는 경우가 있다. 심지어 지금은 간단하게 a, b, c이런식으로 가는데, 유니티만 봐도 막
이름들 엄청길다. 보통 단어와단어들합쳐서 구성하는데
maxNumber
max_number이런식으로 작성을 한다.
위에처럼 maxNumber 이렇게 쓰면 낙타 등같이 생겼다고 해서 카멜케이스, 아래처럼 쓰면 _ 이게 뱀처럼 같다고 스네이크 케이스라고 한다.
카멜케이스에서는 첫 단어를 제외하고 나머지 단어들은 시작할때마다 대문자로 써주고, 밑에는 단어와 단어 사이마다 _ 써주면 끝!
다만, 통일성을 갖추기 위해서, 스네이크만 썼으면 스네이크로 쭉 가고, 카멜을 썼으면 쭉 카멜만 써라.
주석
주석은 프로그램상에서 프로그램이 인식하지 않도록 하는 코드내용이라고 보면된다. 이게 왜 필요하냐?
1000~100000줄 넘어가는 코드가 있는데, 만약에 우리가 오류구문 찾으러고 하는데, 일일이 위치에 뭐가있는지 알 수는 없지 않는가? 남이 짠 코드에서 오류를 또 어떻게 고칠것인가.
주석이라는 것은 일종의 메모장이라서 프로그램이 인식하지 않는다.
/* 이렇게 해도
프로그램이 인식을 안 해요 */
//진짤루에요/* */ 를 통해서 감싸주거나
한줄만 주석처리하고싶으면 //을 이용한다.
'KnockOn' 카테고리의 다른 글
| [KnockOn] Linux/Ubuntu C언어 입출력함수 (1) | 2024.11.14 |
|---|---|
| [KnockOn] Linux/Ubuntu C언어 연산자 (0) | 2024.11.13 |
| [KnockOn] Linux/Ubuntu C언어 및 컴파일 (0) | 2024.11.11 |
| [KnockOn] Linux/Ubuntu SSH, NC (0) | 2024.11.07 |
| [KnockOn] Linux/Ubuntu 방화벽, ufw (1) | 2024.11.07 |